將機器學習縮小到物聯網的大小
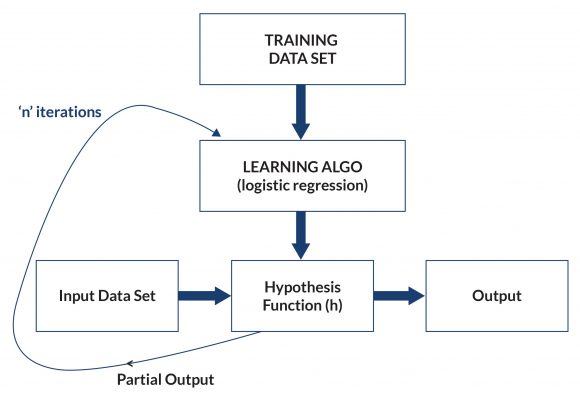
儘管機器學習在嵌入式應用領域擁有極大發展潛力,此技術因為過於複雜仍無法擴大採用率。截至目前,機器學習的發展一直由少數具有數學與電腦科學深厚背景的領域專家推動。於是,一般最終使用者試著在本身的應用中運用機器學習時必須自力更生。一般開發人員所面臨的主要挑戰之一就是缺少資料。在典型的工作流程中,訓練資料會饋入「學習演算法」中,轉而產生「假設函式」,會嘗試複製所期望的行為(圖 1)。接著讓測試資料饋入假設函式中執行,然後再用其結果來優化函式的效能。
通常由領域專家建構訓練資料,他們經常要湊合使用可以取得的任何資料。實地獲取資料十分困難,要在開發過程中從目標系統取得即時資料去測試假設函式更加困難。機器學習演算法因此無法達成可能的最高效率。相關障礙之一是機器學習發展的建模部份過去都需要資料中心等級的運算能力,而且輸出演算法並未針對嵌入式處理器進行調校。所幸能針對嵌入式系統量身打造機器學習的開發工具和硬體平台已開始面市。
機器學習原型與原則
例如,SECO 已經把機器學習模型建構與演算法訓練的元件整合到 UDOO App Inventor (UAPPI) 工具套件。UAPPI 是以 MIT 開放原始碼 App Inventor 2 平台為基礎的 web 型整合式開發環境 (IDE)。
使用 UAPPI 的使用者不需要撰寫任何傳統原始碼即可設計系統和應用程式(圖 2)。相反的,UAPPI 環境的功能是使用每一項邏輯功能的圖形建構組塊來開發和實作。於是可以快速開發核心功能,包括圖形化使用介面 (GUI)、網路連線和資料庫儲存以及機器學習建模和演算法訓練,並建立其原型。
UAPPI 內部的機器學習核心元件是 UdooSvm,這是一種監督式學習模型,以及以支持向量機 (SVM) 為基礎的一套相關資料分類演算法。若提供包含特徵向量和標籤的訓練資料集時,UdooSvm 遇到無標籤的特徵時會使用一個映射函式將它們分類。要深入瞭解 UdooSvm 如何產生適合嵌入式系統使用的機器學習演算法,讓我們用例子來說明。
用機器學習種出更好的香蕉
設想有個系統可以藉由測試細菌所釋出的氣體來判斷香蕉是否成熟。該假設系統包含一個戳有通氣孔的容器內的一根香蕉,並附有一個每隔五分鐘測量空氣成份的氣體感測器陣列。系統最初接受訓練時並不瞭解與「熟度」相關的氣體類型與濃度。因此,由氣體感測器陣列收集的資料一開始被標記為「良好果實」。隨著日子過去,當香蕉完全成熟時空氣成份會改變,然後資料樣本會被標記為「即將腐爛」。香蕉最終會變成黑色,釋出不同的氣體混合物,然後資料被標記為「腐爛水果」。有了這些資料集,便可以使用各種 SVM 核心,包括 Linear、Polynomial 或徑向基函數 (RBF) 核心來建立學習模型。為了判斷他們的準確度,可以從原始訓練資料集擷取測試資料然後與每個模型所產生的演算法做比對(圖 3)。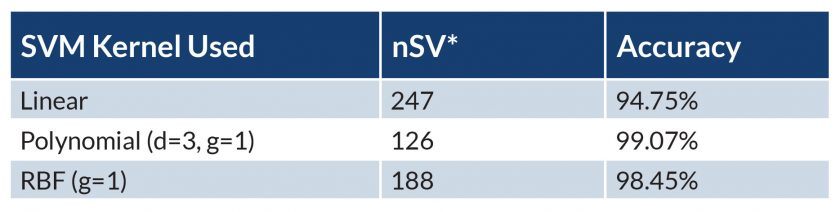
只要選取最準確的學習模型,便可以用來產生用於「熟度」系統的 UdooSvm 演算法。UdooSvm 演算法經過最佳化可在嵌入式處理器目標上執行,但是亦不清楚特定的特徵向量代表什麼,或甚至它們是如何產生出來的。這意味著特徵向量和標籤若是以從嵌入式感測器一類元件所提供的資料為基礎,可以再次送回演算法中,以便隨時間逐漸自主演進。
簡單提高智慧
UAPPI 與 UdooSvm 演算法經過最佳化可與 SECO UDOO 開發板,包括 UDOO x86 Arduino 101 板搭配運作(圖 4)。因為 UDOO x86 與 Arduino 函式庫和擴散板完全相容,開發人員可以從 Arduino 價值鏈體系迅速獲得一系列的感測器,為 UdooSvm 演算法提供即時輸入資料。
可使用 UDOO x86 的處理器包括 Intel Atom® 處理器 X5-E8000、Intel® Celeron® 處理器 N3160,或 Intel® Pentium® 處理器 N3710。這組可擴充的處理器提供全面支援,從僅有數個向量的演算法直至有多個資料來源的複雜應用程式。
機器學習發展自成一格
UAPPI、UdooSvm 和 UDOO x86 並不是唯一可用的機器學習原型工具,但是他們確實透過某種程度的抽象化,讓所有背景的開發人員都得以使用機器學習。再加上 Arduino 價值鏈體系的幫助,可以更快速、更輕鬆地開發精密的機器學習系統。我們已經可以想像不久的將來,用原廠的演算法部署機器學習系統,然後系統利用他們實地擷取的環境資料來自行改善。跟上技術迅速發展的腳步之唯一方式是自動化時,人們無法抗拒可以獨立學習的系統。