讓邊緣裝置上的人工智慧和電腦視覺得以順利擴充

編者註:insight.tech 支持終結種族主義、不平等與社會不正義行為。我們不容忍我們贊助商的產品用於侵犯人權,包括但不限於政府濫用視覺化技術。insight.tech 上所提到的產品、技術和解決方案皆假定為以負責且合乎道德的方式使用人工智慧以及電腦視覺工具、技術和方法。
自 Intel 首次採用多核心設計以來已經過了 15 個年頭。如今,透過使用超過 1 個 Intel® CPU 核心來提高效能的這種作法已從尖端技術變為常見作法。AI 的出現使得開發人員面臨與十幾年前相似的問題。然而,這些問題與異質運算環境的關係在 2004 年並不存。
傳統 CPU 裡有一排相同的核心,每個核心適合獨立作業。CPU+GPU 或 CPU+FPGA 的異質組合則不同,它們結合的是兩個或以上完全不同的元件。這種作法在合適的情況下可以帶來巨大的機會,為兩個元件創造運算上的優勢,但它同時也提高了部署上的困難性。
再加上最適合部署這種耐用型解決方案的環境通常非常險峻,哪怕是比叉子還要稍微高科技的東西,都難以生存。綜合下來,得面對的就是一食譜的問題。
(而且這份食譜還作不出什麼有用的成品,像是酸麵包。不是。就真的只是一堆問題而已。)
要在多個解決方案上擴充工作負載,一方面需要有建造和部署硬體解決方案的專業知識,另一方面需要能進行開發和測試解決方案的軟體環境。Intel® OpenVINO™ 工具組專為這個目的打造。在企業開發同質和異質運算環境時,這個工具組能協助企業在不同類型的裝置上進行擴充。
OpenVINO 中導入的 AI 和機器學習演算法引起許多關注,但 “ V” 代表「視覺」,且該工具箱的許多功能預先訓練了與電腦視覺格外相關的模型。
在不同的硬體平台上進行擴充
OpenVINO 支援 OpenVX 和 OpenCL 等跨平台 API,藉此讓 CPU 和加速器執行工作負載(圖 1)。
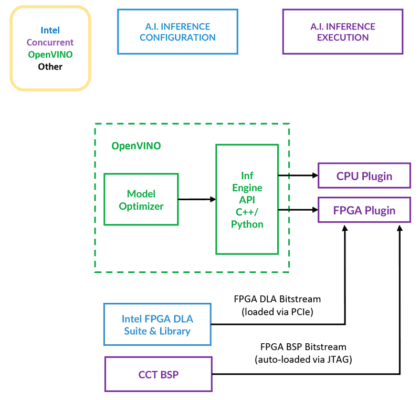
然而,如果沒有相符的硬體,軟體本身並沒甚麼用。在這方面,一些解決方案能幫得上忙,如 Concurrent Technologies 提供的 TR H4x/3sd-RCx 解決方案。這套系統的基礎是一個 3U VPX 系統,配備 12核/24 緒的 Intel® Xeon® D-1559 以及最高 64 GB 的 RAM。
如果以上配置無法滿足客戶需求,客戶可以選擇透過 PCIe 連接額外的處理資源。TR H4x/3sd-RCx 可與 Intel® Arria® FPGA 搭配使用,後者透過 PCIe 連接,能提供額外的處理能力。
最佳化電腦視覺模型
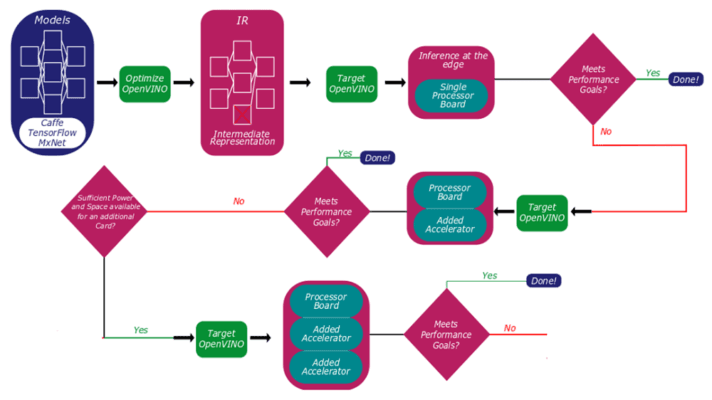
客戶可以利用 OpenVINO 最佳化模型並測試解決方案的效能。一開始採用單處理器,之後依照需求能擴充涵蓋額外的處理資源(圖 2)。
「把模型移到 CPU 上執行的方法很簡單。這方面我們提供一套廣泛的 Linux 支援套件。」Nigel Forrester 表示。他是 Concurrent Technologies 的 Director of Business Development。「要把模型移到 TR H4x 卡上稍微複雜一點。我們在卡上內建了多種支援套件,也提供 DLA,也就是深度學習加速位元流 (Deep Learning Accelerator bitstream)。DLA 是在 Intel Aria FPGA 上執行。」。
「客戶只需要知道自己需要什麼樣的神經網路模型就好。」Forrester 表示。接著,他們只要選擇正確的 DLA 位元流,然後將現有模型放入 OpenVINO。」這會創建一套中繼碼,而中繼碼之後會上傳到加速器。」
之後,OpenVINO 會進行分配,CPU 專屬的程式碼會進行最佳化,然後在 CPU 上執行; FPGA 程式碼則會保留,然後在 Arria 硬體上執行。
我們有 Intel® Deep Learning Accelerator Suite (Intel® DLA) 的開發人員授權,這部分已經匯入我們的 Trax 卡了。」Forrester 表示。「客戶這方面什麼都不用做。他們只要知道自己的神經網路模型是 AlexNet、SqueezeNet、GoogleNet 還是其他模型,並且屬於 TensorFLow 這類框架。」
上方的圖表說明了OpenVINO 模型在 Concurrent TR H4x/3sd-RCx 硬體上如何通關。模型會經歷最佳化、效能測試、硬體部署循環,這個過程旨在幫助開發人員了解應當為哪些工作負載指定哪些資源。隨著新的 Intel GPU 和推斷加速器上市,OpenVINO 在接下來幾年會發揮更大的作用,提高軟體整體的靈活性並讓開發人員能夠針對更廣泛的使用案例和情景進行設計。