AI 效能標竿:建置前的參考

AI 已建置出新一代晶片,其設計可在輸送量、延遲與耗電量之間取得平衡。
GPU、FPGA 和視覺處理器 (VPU) 等 AI 加速器均針對類神經網路工作負載的運算最佳化。這些處理器架構讓電腦視覺 (CV)、語音辨識和自然語言處理等應用得以實現。它們也讓物聯網邊緣裝置上的本機 AI 推斷得以付諸實行。
但是,效能標竿顯示這些加速器的重要性並不相同。選擇任一加速器都可能會對系統輸送量、延遲、耗電量和整體成本造成嚴重影響。
瞭解 AI 推斷
務必確實瞭解何謂類神經網路,以及運算這些網路所需具備的條件。這有助於釐清稍後要檢視的效能標竿。
類神經網路是模擬人類大腦的 AI 技術子集。類神經網路並非單一演算法,它通常是由多個軟體演算法集結而成,層層堆疊,就像蛋糕一樣。
每一層都會對輸入資料集進行分析,然後根據訓練階段學到的特點來加以分類。於某一層將特定特點分類之後,其會將此輸入傳遞給後續層級。在迴旋式類神經網路 (CNN) 中,系統會執行一或多次的線性數學運算 (迴旋) 來產生這些層級的累積運算式。
例如,在影像分類中,網路會收到一張圖片。某一層會將形狀歸類為臉孔。另一層會分類四條腿。第三層可分類毛皮。套用迴旋後,類神經網路最終會推斷這是貓的影像(圖 1)。這個過程稱為「推斷」。

類神經網路處理器每次運算新層級時,都必須存取來自記憶體的輸入資料。取捨就從這裡開始。
類神經網路中的層數和迴旋越多,AI 加速器所需的效能和高頻寬記憶體存取次數就越高。但是,您也可以犧牲精確性來提高速度,或是犧牲速度來降低耗電量。這一切都取決於應用程式的需求。
GPU、FPGA、VPU 之比較
輸送量和延遲效能標竿顯示執行四個精簡影像分類類神經網路時,Intel® Arria® 10 FPGA、Intel® Movidius™ Myriad™ X VPU 和 NVIDIA Tesla GPU 的效能狀況。這些網路為 GoogLeNetv1、ResNet-18、SqueezeNetv1.1 和 ResNet-50。
每個處理器均裝設在現成加速卡中,提供真實世界情境:
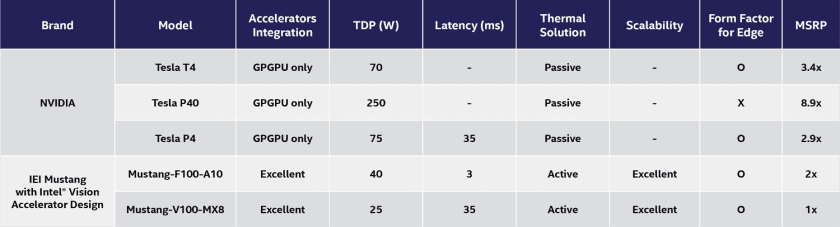
Arria 10 FPGA — 此軟體定義的可程式化邏輯裝置可提供高達每秒 1.5 兆次浮點運算 (TFLOPS) 和整合式 DSP 區塊。IEI Integration Corp. Mustang F100-A10 AI 加速卡在我們的效能標竿中呈現出這一點。
Mustang F100-A10 包含 8 GB 的 2400 MHz DDR4 記憶體和 PCIe 第 3 代 x8 介面。這些特點可支援對超過 20 個同步視訊頻道進行類神經網路推斷(圖 2)。

Myriad X VPU — 這些硬體加速器整合了類神經運算引擎、16 個可程式化 SHAVE 核心、超高輸送量記憶體網狀架構,以及支援高達八個 HD 攝影機感應器的 4K 影像訊號處理 (ISP) 管線。這些資訊都包含在 IEI Mustang-V100-MX8 的效能標竿中。
Mustang-V100-MX8 整合了八個 Movidius X VPU,因此可同時對多個視覺管道執行類神經網路演算法(圖 3)。每個 VPU 都僅耗用 2.5 瓦的電力。

NVIDIA Tesla GPU — 這些推斷加速器採用 NVIDIA Pascal 架構,能以相當於 CPU 1/15 倍的延遲提供 5.5 TFLOPS 的效能。NVIDIA P4 超大規模推斷平台會受到效能標竿的影響。
圖 4 顯示效能標竿結果。輸送量是以每秒分析的影像數來表示,而延遲則代表分析每個影像所需的時間(以毫秒為單位)。
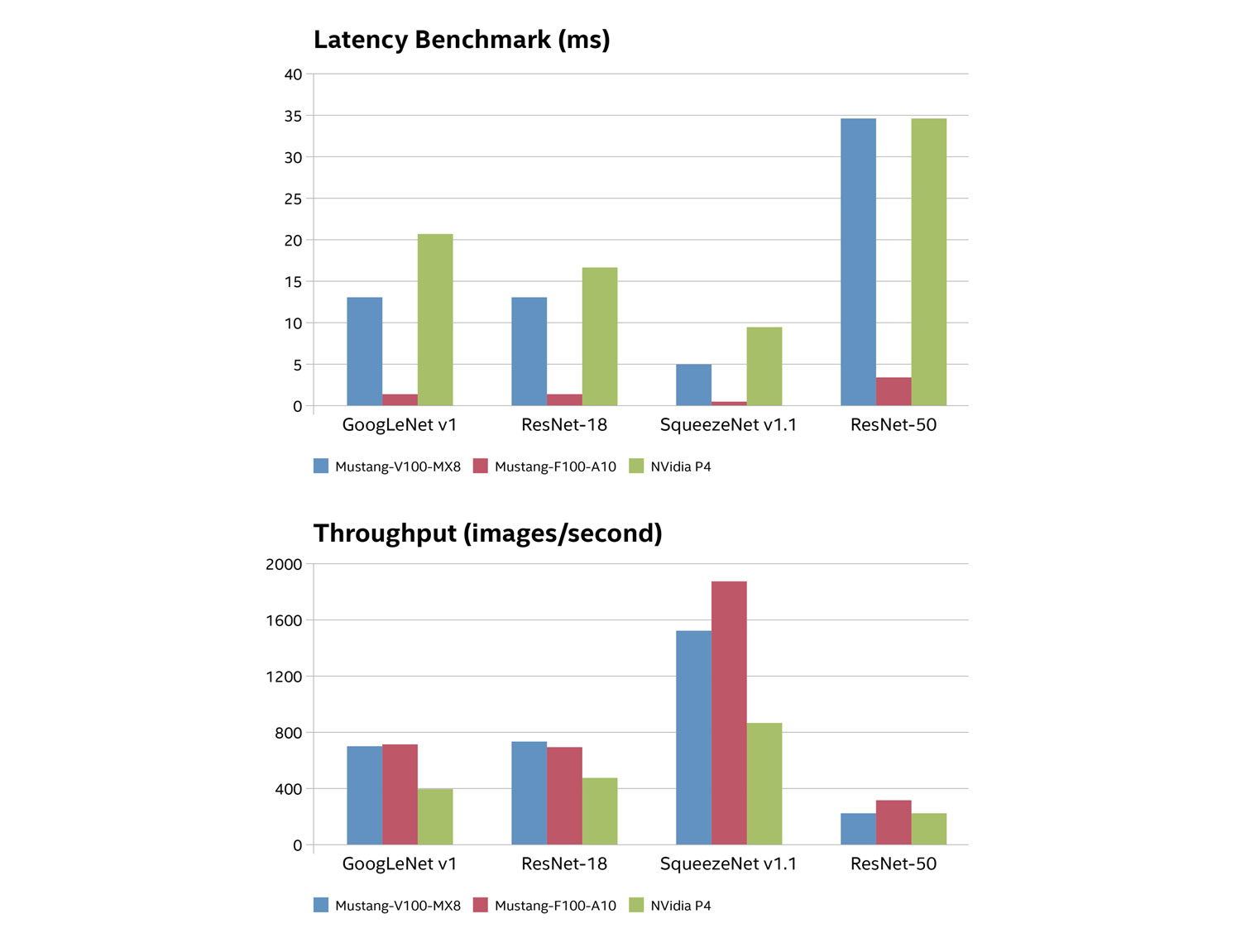
輸送量和延遲效能標竿顯示,以整個類神經網路工作負載來看,FPGA 和 VPU 加速器的效能明顯優於 CPU。如圖 5 所示,IEI Mustang 產品的散熱設計功率 (TDP) 額定值與價位點明顯較低。
除了效能標竿以外的比較
GPU 在這類小批次處理工作上表現較差的原因,與架構有很大的關係。
GPU 通常由含有 32 個核心的區塊組成,所有區塊都是平行執行相同指令。這種單一指令、多重資料 (SIMD) 架構讓 GPU 能夠比傳統處理器更快速地處理大量的複雜工作。
但是,延遲與這些存取記憶體資料的核心有關,而 P4 上的記憶體就是外部 DDR5 SDRAM。在較大的工作負載中,由於平行處理方式能套用多個核心的效能,因此延遲問題不容易被注意到。在較小的工作負載中,延遲比較顯而易見。
相對地,FPGA 和 VPU 因為其架構彈性之故,因此在較小的工作負載中表現優異。
Intel® Arria® 10 FPGA 內部
例如,Arria 10 FPGA 網狀架構可重新設定,以支援不同的邏輯、算術及暫存器等功能。這些功能可以組織成 FPGA 網狀架構的區塊,以符合特定類神經網路演算法的確切需求。
這些裝置也整合了可變精密的 DSP 區塊與浮點功能(圖 6)。這可提供 GPU 的平行處理,而不需要延遲的取捨。
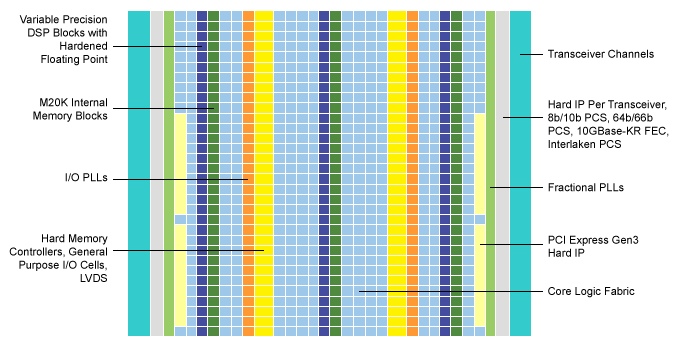
內部記憶體和高頻寬內部互連,讓邏輯區塊可直接存取資料,因而造就超低延遲。因此,Arria 10 裝置可以比 GPU 更快速地擷取和運算小批的推斷資料,進而大幅提高輸送量。
利用 Intel® Movidius™ Myriad™ X VPU 的彈性運算與記憶體
同時,Myriad X VPU 的類神經運算引擎還提供專用的晶片內建 AI 加速器。類神經運算引擎是一種硬體區塊,能以最低耗電量及高達每秒 1 兆次的運算作業 (TOPS) 來處理類神經網路。
類神經運算引擎配備前述的 16 個可程式化 SHAVE 核心。這些 128 位元向量處理器結合成像加速器和硬體編碼器,打造高輸送量的 ISP 管線。事實上,SHAVE 核心可以一次執行多個 ISP 管道。
管線中的每個元件都可以存取共同的智慧記憶體網狀架構(圖 7)。因此,類神經網路工作負載可在經過最佳化的神經運算引擎中終止,不需耗費多重記憶體存取所產生的延遲或電力。

查看效能標竿
本文說明晶片架構與硬體加速器的創新如何在邊緣實現 AI。雖然每種架構各有其優點,但是必須通盤考量這些平台對於類神經網路作業和系統之運算效能、耗電量和延遲有何影響。
為此,請務必先查看效能標竿,再著手進行下一個 AI 設計。