在邊緣 AI 專案中使用超大規模雲端服務平台?請先閱讀下文

您想要建構一套 AI 系統。該從何處著手?
以多模態情感分析為例,其仰賴多個自然語言處理和/或電腦視覺模型,模型透過嚴格的資料標記和訓練最佳化。若要將其應用在零售客服資訊亭,則需要建立基礎架構,如資料庫和視覺化工具、網路應用程式開發環境、部署和交付服務,當然也少不了一兩個 AI 模型訓練架構。
如果這是您首次嘗試使用 AI 建立系統,貴組織可能尚未以利於快速 AI 系統原型設計的方式配置所有工具,甚至沒有具備所有必備的元件。在這種情況下,希望進行 AI 工程者往往會轉而使用 Microsoft Azure、 AWS 和 Google Cloud 等超大規模雲端服務平台。除了具有基本上無限的資料容量和基礎架構服務,許多超大規模雲端服務平台也支援隨時可用的端對端 AI 開發,或者只要按幾下就能為特定第三方工具提供 API 型的整合。
最重要的是,您能以相對經濟實惠的價格開始使用,之後以即服務的形式新增功能。那麼,既然可以自己輕鬆快速地開始使用,又何必組建一個技術合作夥伴的生態系統?
超大規模雲端服務平台對邊緣 AI 工程師的隱藏成本
在概念驗證(PoC)的早期階段,超大規模雲端服務平台非常適合構思創意。但是隨著您愈加接近成品的原型設計階段,它們的侷限性就會很快暴露無遺。
「超大規模雲端服務平台的難處在於製作真正定制的 PoC,因為超大規模雲端服務平台是基於標準運作。您要嘛使用那些標準,要嘛不用超大規模雲端服務平台,」全球資訊與通訊技術公司富士通(Fujitsu Limited)產品業務資料長 Glenn Fitzgerald 表示。「這適用於他們使用的基礎架構與應用程式堆疊。」
「此外還有資料主權與落地權的問題,這在 PoC 階段不是那麼相關,但是進入原型設計階段就變得至關重要,」Fitzgerald 繼續說。「超大規模雲端服務平台不希望您從雲端和結構中擷取資料以規避它。法律和監管問題會大幅增加資料驅動專案的複雜性,這些專案在超大規模雲端環境中使用 AI。」
資料是關鍵。AI 技術取決於不斷增加的資料匯集至訓練模型,進而提高神經網路的準確性和效能,使邊緣核心通訊及資料管理成為關鍵因素。資料儲存是超大規模雲端服務平台的主要收益來源。
不難想像,在超大規模雲端環境中使用幾張圖像啟動 AI PoC,隨著原型的發展,它會擴大為包含數十萬張圖像的多個資料庫。此外,由於從超大規模雲端擷取資料不易,起初貌似無害的平台選擇可能在瞬間淪為昂貴的平台陷阱。
AI 身分識別危機
這個時候,您也應該問自己究竟是否需要開發 AI。比方說,大多數公司並不出售情感分類,而是用它來推動零售資訊亭或市場軟體解決方案。這是因為隨時可用的 AI 並非解決方案,而是可以解決現有問題的一項新功能。
「AI 不是任何問題的解決方案,」Fitzgerald 解釋道。「如果您是從機器學習或自然語言處理或神經網路的傳統意義中思考 AI,在 99% 的情況下它是解決方案的組成元素,而非解決方案本身。
「公司應該從『這是我的業務問題』開始。太多公司的出發點是『我必須做點 AI。』」Fitzgerald 表示。「但是,如果您是從『必須做點 AI』著手,到頭來會一事無成。」
在許多情況下,較好的策略是利用技術生態系統來減輕 AI 模型建立的開銷,同時維持低成本。如果運用得宜,這種方法能讓原始設備製造商和系統整合商利用人工智慧的優勢,同時專注於最終應用。
透過合作夥伴生態系統加速 AI 推斷
富士通與 Intel 及英國諮詢公司 Brainpool.AI 合作,建立了合作夥伴關係,為 AI 原型設計者開啟大門。稱作「共同創造研討會」的公司可接觸 Brainpool.AI 的 600 多位頂尖 AI 學者,其就實現預期結果所需的基礎架構元件提供建議。富士通作為整合商,協調其他合作夥伴並建立必要的基礎架構,透過原型設計從 PoC 擴展 AI。
為了使流程更加順暢,富士通建立 AI Test Drive 這個 Web 型應用程式元件、資料服務、監控工具和 SUSE Linux、NetApp 和 Juniper Networks 的 AI 套件專用 AI 基礎架構。此軟體封裝在一個示範叢集,於搭載 Intel® 處理器的伺服器上執行,以便使用者對 AI 設計進行壓力測試,同時保留對其資料的 100% 控制,進而管理、擷取及清理。
可以透過入口網站存取 AI Test Drive 的免費試用版。為了在 AI 使用案例範圍提供一流的模型精確度、延遲性和效能,它使用 Intel® OpenVINO™ 工具組。
此工具組是一個 AI 模型最佳化套件,可以壓縮及加速在不同環境中產生的不同神經網路軟體,以便在不同硬體上使用。它與 Open Model Zoo 相容,因此可以將預先訓練模型輕鬆匯入原型製作流程中。
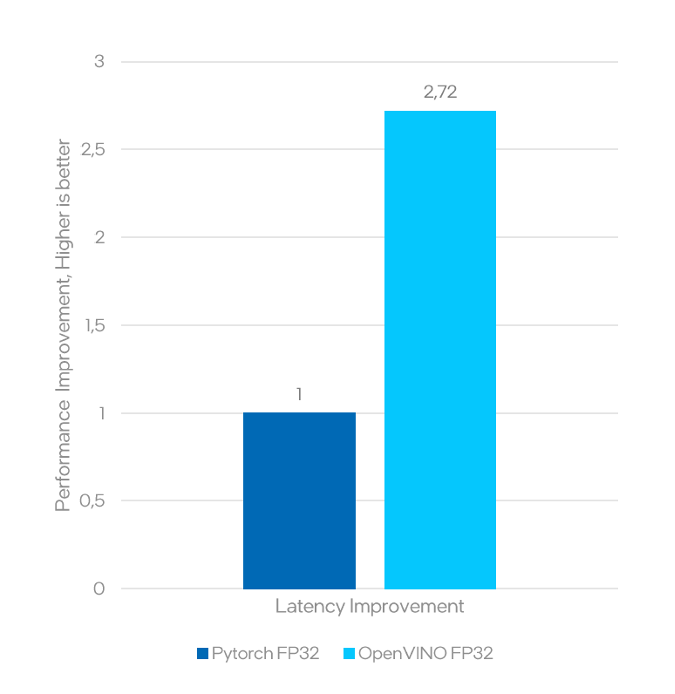
如圖 1 所示,與同一個未最佳化的 PyTorch FP32 模型相比,OpenVINO 將 FP32 BERT 情感分類模型加速了 2.68 倍。
「您必須建立一個適合您試圖解決問題的生態系統,」Fitzgerald 表示。「像富士通這樣的組織,可以將其他組織納入其中並涵蓋所有基礎,這就是您獲得最佳團隊來解決問題的方式,」Fitzgerald 如是說。
從業務問題著手
如今各行各業都擔心自己未在邊緣 AI、視覺 AI 和機器學習中搶佔先機。但在被這股風潮席捲之前,請先瞭解該如何避免一窩蜂地隨波逐流,在不屬於自己專長的領域逞能。
「從業務問題著手,」Fitzgerald 建議。「如果您瞭解業務問題所在,接著便能與利害關係人、您信任的合作夥伴與第三方合作,攜手解決那項問題。」